0. 背景介绍
说起Too many open files这个报错,想必大家一定不陌生。在Linux系统下,如果程序打开文件句柄数(包括网络连接、本地文件等)超出系统设置,就会抛出这个错误。
不过最近发现Tomcat的类加载机制在某些情况下也会触发这个问题。今天就来分享下问题的排查过程、问题产生的原因以及后续优化的一些措施。
在正式分享之前,先简单介绍下背景。
Apollo配置中心(https://github.com/ctripcorp/apollo)是携程框架研发部(笔者供职部门)推出的配置管理平台,提供了配置中心化管理、配置修改后实时推送等功能。
有一个Java Web应用接入了Apollo配置中心,所以用户在配置中心修改完配置后,配置中心就会实时地把最新的配置推送给该应用。
1. 故障现象
某天中午,开发在生产环境照常通过配置中心修改了应用配置后,发现应用开始大量报错。
查看日志,发现原来是redis无法获取到连接了,所以导致接口大量报错。
Caused by: redis.clients.jedis.exceptions.JedisConnectionException: Could not get a resource from the pool
at redis.clients.util.Pool.getResource(Pool.java:50)
at redis.clients.jedis.JedisPool.getResource(JedisPool.java:99)
at credis.java.client.entity.RedisServer.getJedisClient(RedisServer.java:219)
at credis.java.client.util.ServerHelper.execute(ServerHelper.java:34)
... 40 more
Caused by: redis.clients.jedis.exceptions.JedisConnectionException: java.net.SocketException: Too many open files
at redis.clients.jedis.Connection.connect(Connection.java:164)
at redis.clients.jedis.BinaryClient.connect(BinaryClient.java:82)
at redis.clients.jedis.BinaryJedis.connect(BinaryJedis.java:1641)
at redis.clients.jedis.JedisFactory.makeObject(JedisFactory.java:85)
at org.apache.commons.pool2.impl.GenericObjectPool.create(GenericObjectPool.java:868)
at org.apache.commons.pool2.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:435)
at org.apache.commons.pool2.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:363)
at redis.clients.util.Pool.getResource(Pool.java:48)
... 43 more
Caused by: java.net.SocketException: Too many open files
at java.net.Socket.createImpl(Socket.java:447)
at java.net.Socket.getImpl(Socket.java:510)
at java.net.Socket.setReuseAddress(Socket.java:1396)
at redis.clients.jedis.Connection.connect(Connection.java:148)
... 50 more
由于该应用是基础服务,有很多上层应用依赖它,所以导致了一系列连锁反应。情急之下,只能把所有机器上的Tomcat都重启了一遍,故障恢复。
2. 初步分析
由于故障发生的时间和配置中心修改配置十分吻合,所以后来立马联系我们来一起帮忙排查问题(配置中心是我们维护的)。不过我们得到通知时,故障已经恢复,应用也已经重启,所以没了现场。只好依赖于日志和CAT(实时应用监控平台)来尝试找到一些线索。
从CAT监控上看,该应用集群共20台机器,不过在配置客户端获取到最新配置,准备通知应用该次配置的变化详情时,只有5台通知成功,15台通知失败。
其中15台通知失败机器的JVM似乎有些问题,报了无法加载类的错误(NoClassDefFoundError),错误信息被catch住并记录到了CAT。
5台成功的信息如下:
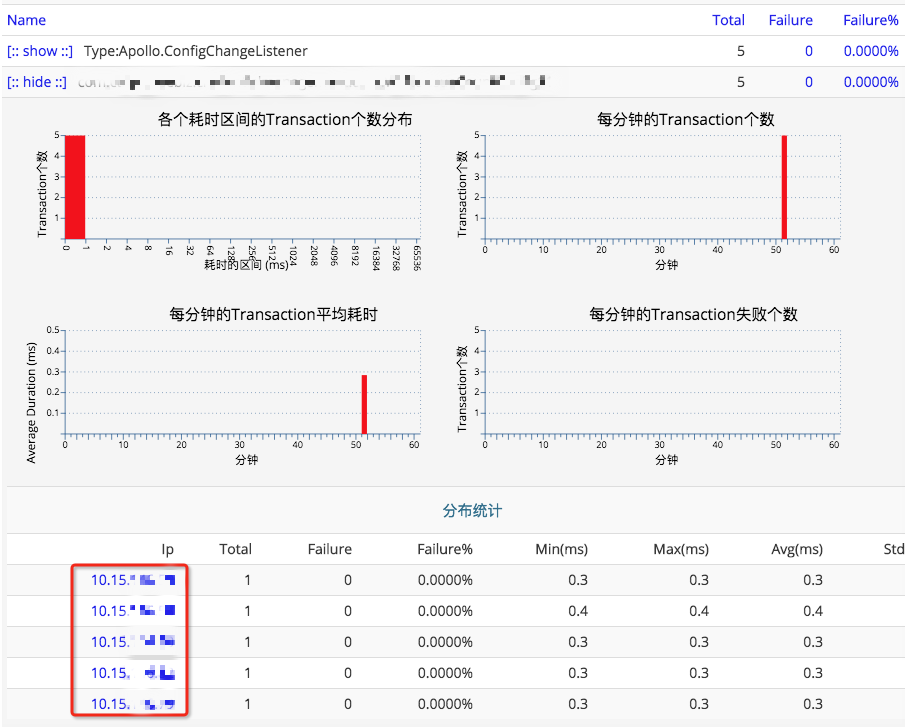
15台失败的如下:
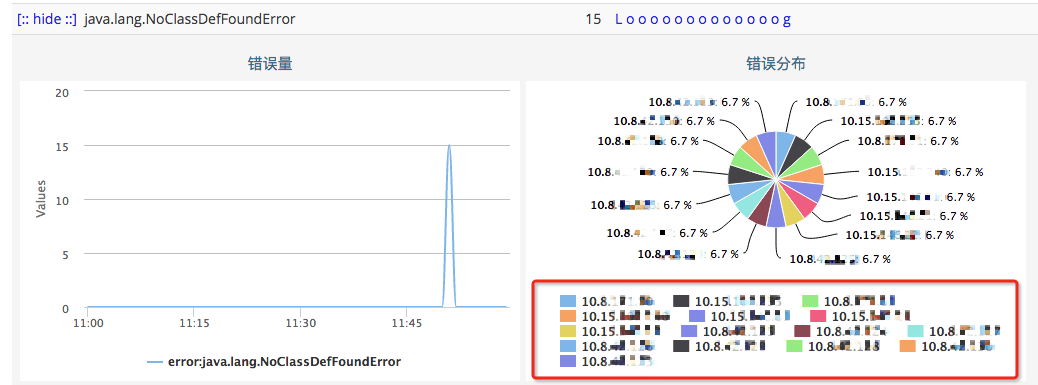
报错详情如下:
java.lang.NoClassDefFoundError: com/ctrip/framework/apollo/model/ConfigChange
...
Caused by: java.lang.ClassNotFoundException: com.ctrip.framework.apollo.model.ConfigChange
at org.apache.catalina.loader.WebappClassLoader.loadClass(WebappClassLoader.java:1718)
at org.apache.catalina.loader.WebappClassLoader.loadClass(WebappClassLoader.java:1569)
... 16 more
配置客户端在配置更新后,会计算配置的变化并通知到应用。配置的变化会通过
ConfigChange对象存储。由于是该应用启动后第一次配置变化,所以
ConfigChange类是第一次使用到,基于JVM的懒加载机制,这时会触发一次类加载过程。
这里就有一个疑问来了,为啥JVM会无法加载类?这个类com.ctrip.framework.apollo.model.ConfigChange和配置客户端其它的类是打在同一个jar包里的,不应该出现NoClassDefFoundError的情况。
而且,碰巧的是,后续redis报无法连接错误的也正是这15台报了NoClassDefFoundError的机器。
联想到前面的报错Too many open files,会不会也是由于文件句柄数不够,所以导致JVM无法从文件系统读取jar包,从而导致NoClassDefFoundError ?
3. 故障原因
关于该应用出现的问题,种种迹象表明那个时段应该是进程句柄数不够引起的,例如无法从本地加载文件,无法建立redis连接,无法发起网络请求等等。
前一阵我们的一个应用也出现了这个问题,当时发现老机器的Max Open Files设置是65536,但是一批新机器上的Max Open Files都被误设置为4096了。
虽然后来运维帮忙统一修复了这个设置问题,但是需要重启才会生效。所以目前生产环境还有相当一部分机器的Max Open Files是4096。
所以,我们登陆到其中一台出问题的机器上去查看是否存在这个问题。但是出问题的应用已经重启,无法获取到应用当时的情况。不过好在该机器上还部署了另外的应用,pid为16112。通过查看/proc/16112/limits文件,发现里面的Max Open Files是4096。
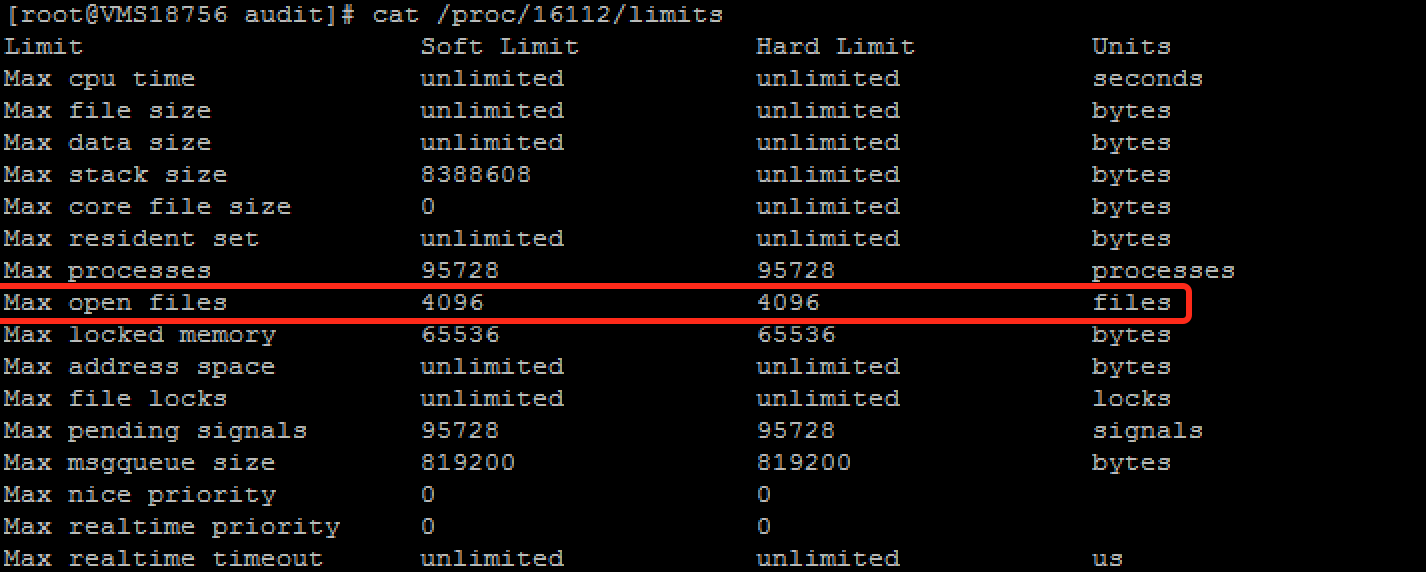
所以有理由相信应用出问题的时候,它的Max Open Files也是4096,一旦当时的句柄数达到4096的话,就会导致后续所有的IO都出现问题。
所以故障原因算是找到了,是由于Max Open Files的设置太小,一旦进程打开的文件句柄数达到4096,后续的所有请求(文件IO,网络IO)都会失败。
由于该应用依赖了redis,所以一旦一段时间内无法连接redis,就会导致请求大量超时,造成请求堆积,进入恶性循环。(好在SOA框架有熔断和限流机制,所以问题影响只持续了几分钟)
4. 疑团重重
故障原因算是找到了,各方似乎对这个答案还算满意。不过还是有一个疑问一直在心头萦绕,为啥故障发生时间这么凑巧,就发生在用户通过配置中心发布配置后?
为啥在配置发布前,系统打开的文件句柄还小于4096,在配置发布后就超过了?
难道配置客户端在配置发布后会大量打开文件句柄?
4.1 代码分析
通过对配置客户端的代码分析,在配置中心推送配置后,客户端做了以下几件事情:
- 之前断开的http long polling会重新连接
- 会有一个异步task去服务器获取最新配置
- 获取到最新配置后会写入本地文件
- 写入本地文件成功后,会计算diff并通知到应用
从上面的步骤可以看出,第1步会重新建立之前断开的连接,所以不算新增,第2步和第3步会短暂的各新增一个文件句柄(一次网络请求和一次本地IO),不过执行完后都会释放掉。
4.2 尝试重现
代码看了几遍也没看出问题,于是尝试重现问题,所以在本地起了一个demo应用(命令行程序,非web),尝试操作配置发布来重现,同时通过bash脚本实时记录打开文件信息,以便后续分析。
for i in {1..1000}
do
lsof -p 91742 > /tmp/20161101/$i.log
sleep 0.01
done
然而本地多次测试后都没有发现文件句柄数增加的情况,虽然洗清了配置客户端的嫌疑,但是问题的答案却似乎依然在风中飘着,该如何解释观测到的种种现象呢?
5. 柳暗花明
尝试自己重现问题无果后,只剩下最后一招了 - 通过应用的程序直接重现问题。
为了不影响应用,我把应用的war包连同使用的Tomcat在测试环境又独立部署了一份。不想竟然很快就发现了导致问题的原因。
原来Tomcat对webapp有一套自己的WebappClassLoader,它在启动的过程中会打开应用依赖的jar包来加载class信息,但是过一段时间就会把打开的jar包全部关闭从而释放资源。
然而如果后面需要加载某个新的class的时候,会把之前所有的jar包全部重新打开一遍,然后再从中找到对应的jar来加载。加载完后过一段时间会再一次全部释放掉。
所以应用依赖的jar包越多,同时打开的文件句柄数也会越多。
同时,我们在Tomcat的源码中也找到了上述WebappClassLoader的逻辑。
之前的重现实验最大的问题就是没有完全复现应用出问题时的场景,如果当时就直接测试了Tomcat,问题原因就能更早的发现。
5.1 重现环境分析
5.1.1 Tomcat刚启动完
刚启动完,进程打开的句柄数是443。
lsof -p 31188 | wc -l
443
5.1.2 Tomcat启动完过了几分钟左右
启动完过了几分钟后,再次查看,发现只剩192个了。仔细比较了一下其中的差异,发现WEB-INF/lib下的jar包句柄全释放了。
lsof -p 31188 | wc -l
192
lsof -p 31188 | grep "WEB-INF/lib" | wc -l
0
5.1.3 配置发布后2秒左右
然后通过配置中心做了一次配置发布,再次查看,发现一下子又涨到422了。其中的差异恰好就是WEB-INF/lib下的jar包句柄数。从下面的命令可以看到,WEB-INF/lib下的jar包文件句柄数有228个之多。
lsof -p 31188 | wc -l
422
lsof -p 31188 | grep "WEB-INF/lib" | wc -l
228
5.1.4 配置发布30秒后
过了约30秒后,WEB-INF/lib下的jar包句柄又全部释放了。
lsof -p 31188 | wc -l
194
lsof -p 31188 | grep "WEB-INF/lib" | wc -l
0
5.2 Tomcat WebappClassLoader逻辑
通过查看Tomcat(7.0.72版本)的WebappClassLoader逻辑,也印证了我们的实验结果。
5.2.1 加载类逻辑
Tomcat在加载class时,会首先打开所有的jar文件,然后遍历找到对应的jar去加载:
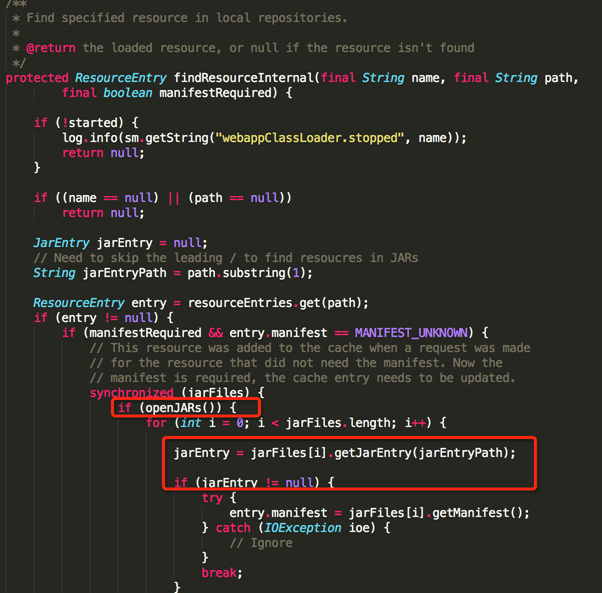
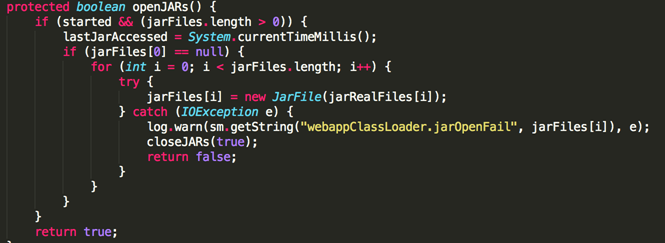
5.2.2 关闭jar文件逻辑
同时会有一个后台线程定期执行文件的关闭动作来释放资源:
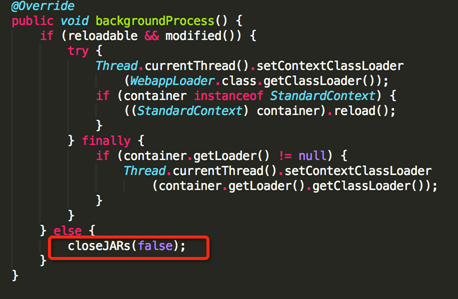
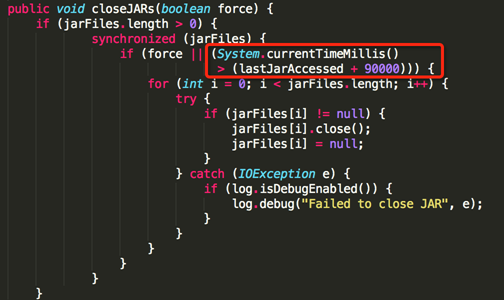
5.3 故障场景分析
对于应用出现故障的场景,由于是应用启动后第一次配置变化,所以会使用到一个之前没有引用过的class: com.ctrip.framework.apollo.model.ConfigChange,进而会触发Tomcat类加载,并最终打开所有依赖的jar包,从而导致在很短的时间内进程句柄数升高。(对该应用而言,之前测试下来的数字是228)。
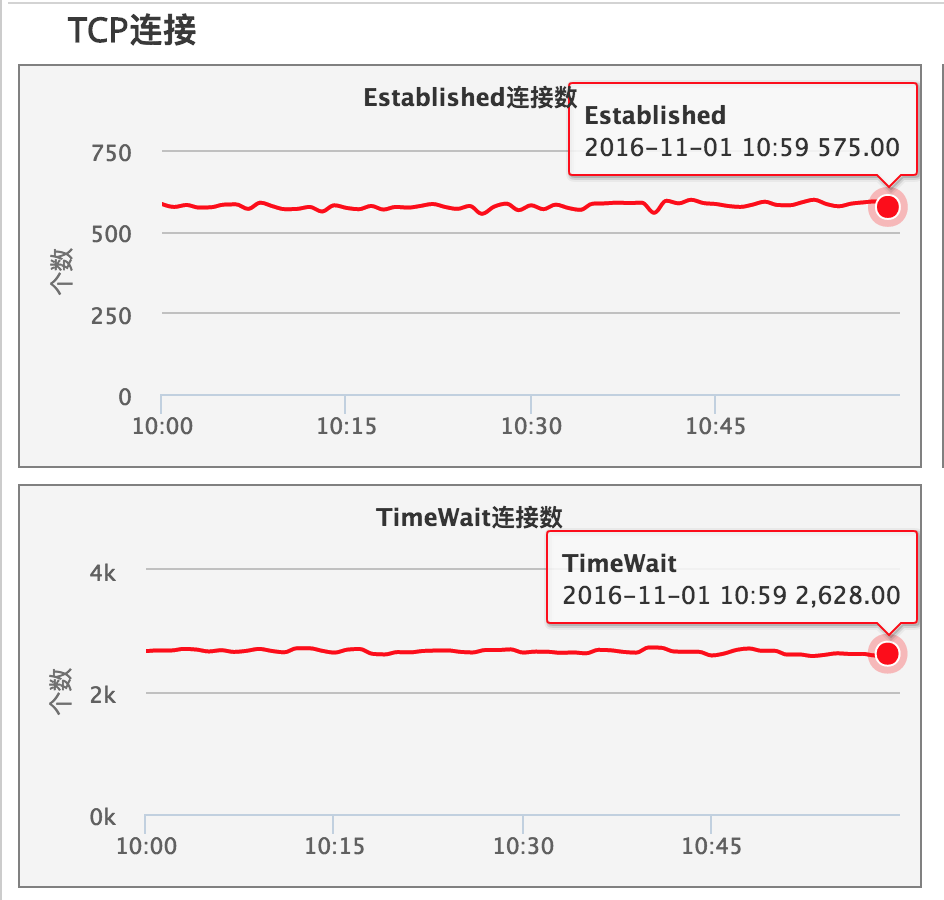
虽然现在无从知晓该应用在出问题前总的文件句柄数,但是从CAT监控可以看到光TCP连接数(Established和TimeWait之和)就在3200+了,再加上一些jdk加载的类库(这部分Tomcat不会释放)和本地文件等,应该离4096的上限相差不多了。所以这时候如果Tomcat再一下子打开本地228个文件,自然就很容易导致Too many open files的问题了。
6. 总结
6.1 问题产生原因
所以,分析到这里,整件事情的脉络就清晰了:
- 应用的Max Open Files限制设置成了4096
- 应用自身的文件句柄数较高,已经接近了4096
- 用户在配置中心操作了一次配置发布,由于Tomcat的类加载机制,会导致瞬间打开本地200多个文件,从而迅速达到4096上限
- Jedis在运行过程中需要和Redis重新建立连接,然而由于文件句柄数已经超出上限,所以连接失败
- 应用对外的服务由于无法连接Redis,导致请求超时,客户端请求堆积,陷入恶性循环
6.2 后续优化措施
通过这次问题排查,我们不仅对Too many open files这一问题有了更深的认识,对平时不太关心的Tomcat类加载机制也有了一定了解,同时也简单总结下未来可以优化的地方:
-
操作系统配置
从这次的例子可以看出,我们不仅要关心应用内部,对系统的一些设置也需要保持一定的关注。如这次的Max Open Files配置,对于普通应用,如果流量不大的话,使用4096估计也OK。但是对于对外提供服务的应用,4096就显得太小了。
-
统一机器配置
公司内的机器配置(如Max Open Files)应该由ops统一管理和调整,一方面可以避免不正确的配置问题,另一方面如果发现有问题,可以统一处理。
-
应用监控、报警
对应用的监控、报警还得继续跟上。比如是否以后可以增加对应用的连接数指标进行监控,一旦超过一定的阈值,就报警。从而可以避免突然系统出现问题,陷于被动。
-
中间件客户端及早初始化
鉴于Tomcat的类加载机制,中间件客户端应该在程序启动的时候做好初始化动作,同时把所有的类都加载一遍,从而避免后续在运行过程中由于加载类而产生一些诡异的问题。
-
遇到故障,不要慌张,保留现场
生产环境遇到故障,不要慌张,如果一时无法解决问题的话,可以通过重启解决。不过应该至少保留一台有问题的机器,从而为后面排查问题提供有利线索。
